Conway’s Game of Life:
Genetic Algorithm for Metuselahs
This project implements a genetic algorithm to discover configurations in Conway’s Game of Life that
meet specific criteria, showcasing the power of AI in software development. This project was
developed for the Biological Computation (20581) Advanced Course at the Open
University of Israel in 2024 and earned a perfect score of 100/100.

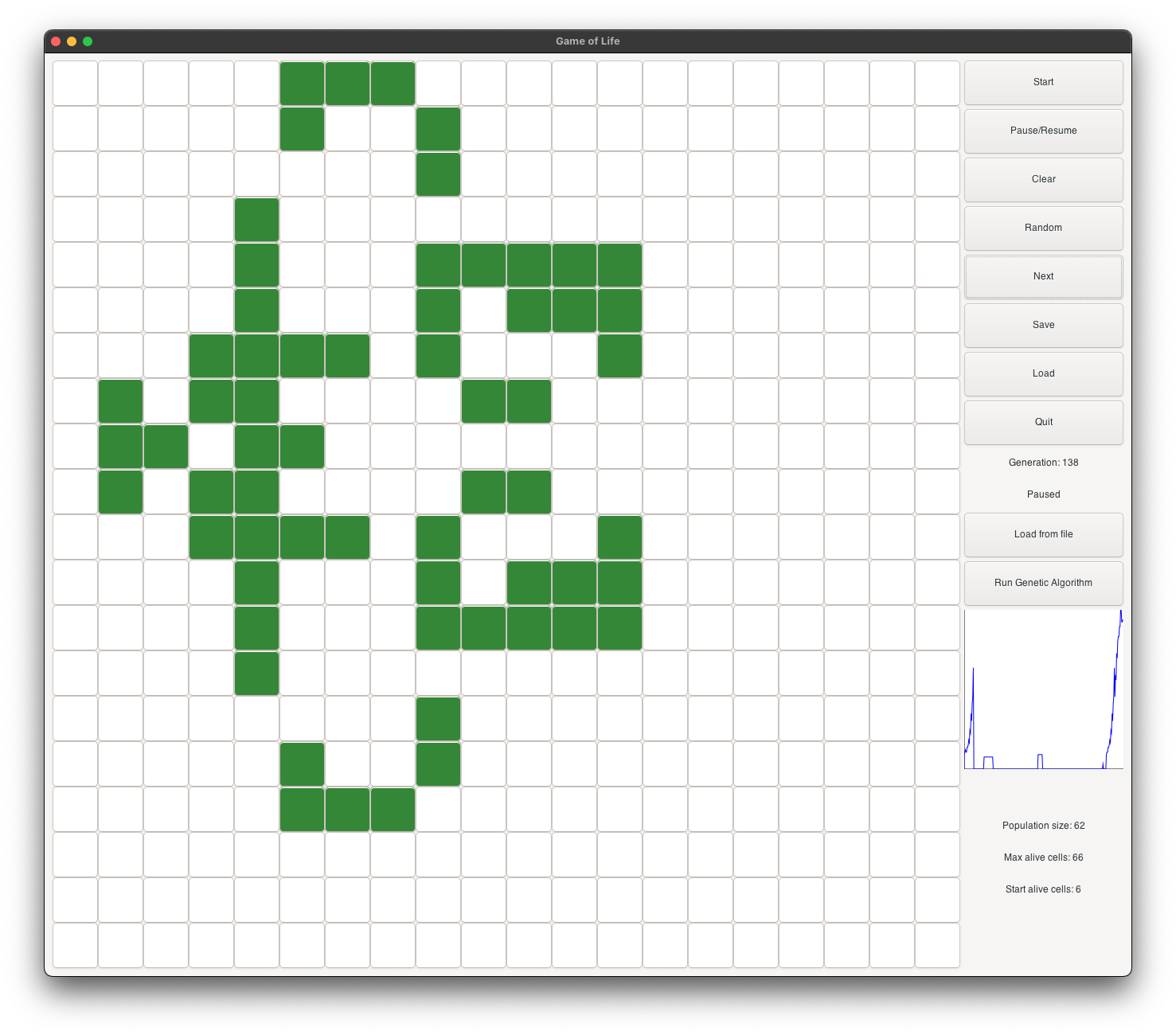
Evolution of a fitted individual in the GUI, blue theme
- Overview
- Getting Started
- Examples
- More Examples
- Technical Details
- Contributions and Feedback
- Acknowledgements
- License
Overview
Before diving into the project, let’s take a look at some patterns discovered by the algorithm. Keep in mind that the algorithm generates different results each time it’s run. The examples in this file represent just a handful of the many patterns that have been identified.
⏳ Please Wait: the animations might take some time to load. It is recommended to wait for the page to fully load before scrolling down, and use a desktop browser for the best experience.


Evolution animation of a fitted individual, displayed in the GUI with a metal blue theme (left)
and a metal red theme (right).
Full GIF versions of all evaluations can be found in the `images` directory.


Zoomed in view of the GUI
The 3D effect is created using the box-shadow property and gradient background (see the CSS file
for more details).
For more examples, please refer to the Examples section.
Background
The Game of Life is a cellular automaton devised by the
British mathematician John Horton Conway in 1970. It is a zero-player game, meaning that its
evolution is determined by its initial state, requiring no further input. The game unfolds on an
infinite two-dimensional grid, with each cell in the grid being either alive or dead. The game
progresses through generations, with each generation determined by the previous one according to
only four rules:
-
Underpopulation: Any live cell with fewer than two live neighbors dies, as if by underpopulation.
-
Survival: Any live cell with two or three live neighbors lives on to the next generation.
-
Overpopulation: Any live cell with more than three live neighbors dies, as if by overpopulation.
-
Reproduction: Any dead cell with exactly three live neighbors becomes a live cell, as if by reproduction.

Example of Rule 1: Underpopulation (left) and Rule 2: Survival (right)


Blinker Shape (left) and Glider Shape (right)
Rule 3 and 4 (Overpopulation and Reproduction) create interesting patterns in the Game of
Life
The project is focused on evolutionary algorithms for optimizations problem, and Conway’s Game of Life serves as the world or the search space for the genetic algorithm. The algorithm is designed with a level of abstraction that allows it to be applicable to any problem that can be modeled as a search space. For a deeper understanding of the Game of Life, refer to its Wikipedia page.
The concept of an Evolutionary algorithm
encompasses a group of algorithms inspired by evolution to solve various problems, primarily
optimization problems, although not limited to them. The core idea involves initializing a
population of potential solutions and leveraging an evolution-inspired process to refine this
population based on the principle of survival of the fittest. Initially, each
solution in the population undergoes evaluation using a fitness function to assess its quality and
likelihood for selection in subsequent generations. The next generation is then formed by selecting
the best solutions from the current generation and subjecting them to crossover and mutation operations. This iterative process
continues until predefined criteria are met. Key characteristics of evolutionary algorithms include
simultaneous evolution of a solution population,
incorporation of crossover mechanisms, and
introducing stochasticity in the
optimization process.

Uniform Crossover
Two parents (up) are combined to create a new child (down).
Child have a 50% chance to inherit each cell from one of the parents.
In this case the child fitness seems to be better than the its left parent, but worse than the
right parent.
A Genetic algorithm represents a specific
instance within the evolutionary algorithm family, emphasizing selection, crossover or recombination, and mutation operations to refine the solution
population. As highlighted in the book, genetic algorithms typically prioritize the crossover phase over mutation. Additionally, they commonly employ
binary representations for solutions and
utilize fitness functions` to evaluate
solution quality, although alternative representations may sometimes yield better results. Genetic
algorithms leverage individuals for exploring new solution directions while preserving promising
solutions. They are particularly effective in identifying promising areas within the search space
rather than focusing solely on finding the optimal solution within those regions.
Genetic Programming constitutes an
evolutionary computation model where solutions are represented as programs, often structured as
trees. The distinctive aspect lies in the genetic operations performed on these program
representations. Mutation involves altering the tree structure, while crossover entails swapping
subtrees. Genetic programming incorporates the concepts of terminals set and functions set, where the former encompasses
all possible terminals in the tree, and the latter includes all possible functions. Another notable
difference lies in the chromosome representation: genetic programming may involve trees of varying
sizes, contrasting with genetic algorithms where chromosomes typically have uniform sizes.
To summarize, the flow of the genetic algorithm is as follows:
\( p_0 \rightarrow \text{Evaluation} \rightarrow \text{Selection} \rightarrow \text{Crossover} \rightarrow \text{Mutation} \rightarrow \)
\( p_1 \rightarrow \text{Evaluation} \rightarrow \text{Selection} \rightarrow \text{Crossover} \rightarrow \text{Mutation} \rightarrow \)
\( p_2 \rightarrow \text{Evaluation} \rightarrow \text{Selection} \rightarrow \text{Crossover} \rightarrow \text{Mutation} \rightarrow \ldots \)
where \( p_0 \) is the initial population, and \( p_1, p_2, \ldots \) are the next generations. The algorithm continues until a stopping criterion is met, such as a maximum number of generations or a satisfactory solution.
Project Objectives
The program utilising a genetic algorithm in order to discover configurations in Conway’s Game of Life that meet the following criteria:
-
Reach a Stable State: The configuration must end in a state that is static or oscillating, containing at least one live cell.
-
Long Evolution Time: The configuration should take a considerable amount of time to reach stability.
-
Expansion Before Stability: During evolution, the configuration must expand significantly beyond its initial size.
This kind of patterns are known as Methuselahs in the Game of Life terminology.
The project aims to explore the potential of genetic algorithms in discovering such configurations,
showcasing the power of AI in software development. For more about Methuselahs, you can visit the Wikipedia page.

Start of the evolution of a fitted individual in the GUI.
Note: (a) Small initial size (b) Large population size at its peak (c) Long time to reach a
stable state. Other factors could have been considered, such as symmetry, but were not
implemented.
Project Structure
The implementation is modular, consisting of:
-
Chromosome Representation:
chromosome.cpp- Encapsulates a configuration within the game, implementing genetic operations like crossover and mutation. -
Genetic Algorithm Core:
ga.cpp&population.cpp- The heart of the genetic algorithm, handling the population of configurations and their evolution over generations. -
Game Logic:
game.cpp- A Game of Life implementation optimized for speed, using C-style memory management for efficiency. -
GUI:
gui.cpp- An advanced graphical user interface for real-time visualization of the algorithm’s progress. -
Main Application:
main.cpp- Orchestrates the execution of all components.
The program utilizes advanced C++ features and design patterns to ensure efficiency, modularity, and scalability. For a detailes explanation of the implementation, please refer to the Technical Details section (previous knowledge of C++ is recommended).
Getting Started
The program is designed to be user-friendly, offering both a graphical user interface (GUI) and
command line execution. The GUI is required installion of the gtk library. If you are not interested in
the GUI, please refer to the Using the Command Line section.
Using the GUI

Graphical User Interface (GUI) for the Genetic Algorithm
The GUI, implemented in gui.cpp, utilizes
the gtk library to deliver an intuitive
user experience. It presents a real-time interactive game display, highlighting key metrics such as
the current generation, the count of initial and currently alive cells, and the top score. It also
includes a graphical representation of the population size, with the flexibility to manually or
automatically execute the algorithm.
This GUI, designed to be user-friendly, provides a real-time visualization platform for the genetic algorithm’s progress. Its intuitive and interactive design ensures a seamless user experience, enabling users to monitor the algorithm’s execution and delve into the results.
To ensure thread safety and enhance responsiveness, the GUI employs a Mutex to synchronize access to its board.
This allows all I/O calls to be made from the main thread, thereby enhancing stability and
preventing potential crashes or freezes.
Before running the GUI, ensure the gtk
library is installed on your system. If absent, it can be installed with the following command:
sudo apt-get install libgtk-3-dev
or on mac:
brew install gtk+3
The program can be compiled with the included makefile by running the following command:
make
After compilation, the GUI can be launched by executing the following command:
../met
The GUI window will appear, providing a comprehensive interface for executing the genetic algorithm. Users can interact with the GUI to tye the game of life, initiate the algorithm, monitor its progress, and explore the evolving configurations within the Game of Life.

Game of Life Interactive Board in the GUI
Click on the cells to toggle their state (alive or dead). For the full version, please see
`https://raw.githubusercontent.com/Dor-sketch/game-of-life-ai/main/images/game.gif`.
The GUI window is compartmentalized into three primary sections:
-
Game of Life Board: This section visually represents the current state of the Game of Life board, dynamically illustrating the evolving configurations.
-
A distinctive feature of the board is its ability to track the age of each cell, in addition to the overall configuration. This capability enables users to color-code cells according to their age, thereby enriching the visualization of the algorithm’s progression and offering insights into the evolution of configurations.
-
The board also offers the flexibility to toggle the grid display. Users can choose to view or hide the grid as per their preference, which enhances the clarity of the board’s structure and improves the overall user experience.
-
-
Control Panel: This section provides users with a range of interactive controls to manage the genetic algorithm’s execution. Key functionalities include:
-
Start \ Pause: Enables users to initiate or pause the Game of Life simulation, providing control over the algorithm’s execution and facilitating real-time monitoring of the evolving configurations. -
Clear: Allows users to reset the board to its initial state, clearing all cells and enabling the creation of new configurations. This feature enhances user flexibility and enables the exploration of diverse configurations within the Game of Life. -
Random: Facilitates the generation of random configurations on the board, enabling users to explore a variety of initial states and observe the algorithm’s evolution from different starting points. This feature enhances user engagement and provides opportunities for experimentation and exploration. -
Next: Allows users to advance the simulation by a single generation, enabling step-by-step progression through the algorithm’s execution. This feature enhances user control and provides detailed insights into the evolution of configurations. -
Save: Facilitates the archiving of current configurations as.txtfiles within thesavesdirectory. This feature ensures that users can preserve their current configurations for future reference and analysis, enhancing the program’s utility and enabling users to revisit specific configurations as needed. -
Run GA: Initiates the genetic algorithm’s execution, enabling users to observe the algorithm’s progress in real-time. This feature offers a streamlined approach to executing the algorithm, enhancing user convenience and facilitating efficient monitoring of the algorithm’s evolution. -
Load: Enables users to load saved configurations from thesavesdirectory, providing access to previously executed configurations for further analysis and exploration. This feature enhances user flexibility and enables the retrieval of specific configurations for detailed examination. -
Quit: Provides users with a convenient option to exit the GUI, ensuring a seamless user experience and enabling users to conclude their interaction with the program efficiently. -
Change Theme: Allows users to personalize the GUI’s appearance by loading customcssfiles. This feature enhances user customization options, enabling users to tailor the GUI’s visual style to their preferences and create a personalized user experience.
-
-
Information Panel: This section offers users a comprehensive overview of the algorithm’s progress, displaying key metrics and insights to enhance user understanding and facilitate informed decision-making. The information panel includes:
-
Generation: Displays the current generation number, enabling users to track the algorithm’s progress and monitor the evolution of configurations over successive generations. -
Population Size: Illustrates the size of the population, offering users a visual representation of the algorithm’s progress and enabling users to track the evolution of configurations over successive generations. -
Currently Alive Cells: Highlights the current count of alive cells in the evolving configuration, enabling users to monitor the algorithm’s progress and observe the development of configurations over time. -
Max Alive: Showcases the maximum alive cells in a generation of the current board configuration, providing users with insights into the algorithm’s performance and the evolution of configurations over successive generations. -
Initial Alive Cells: Indicates the count of alive cells in the initial generation of the current board configuration, enabling users to track the algorithm’s progress and observe the development of configurations over time.
-
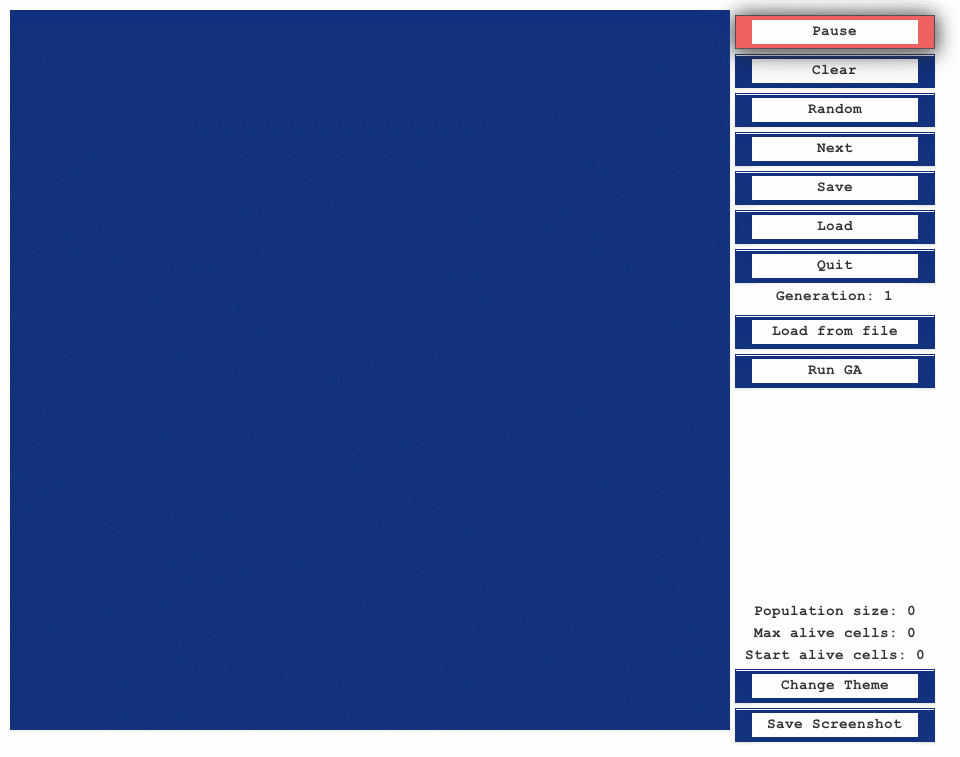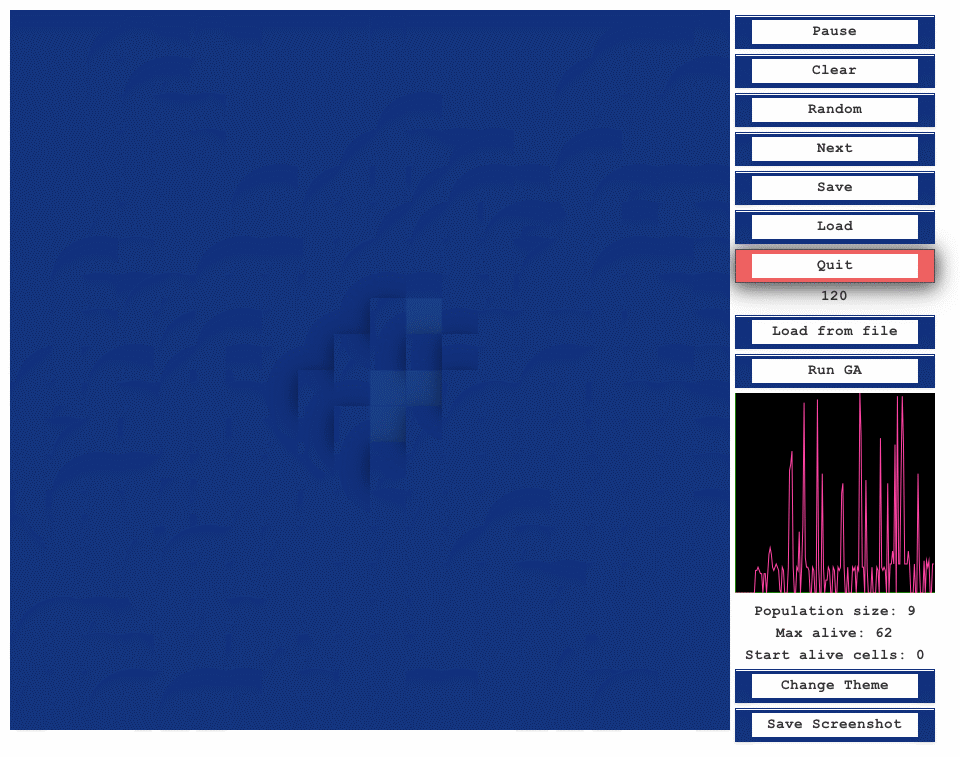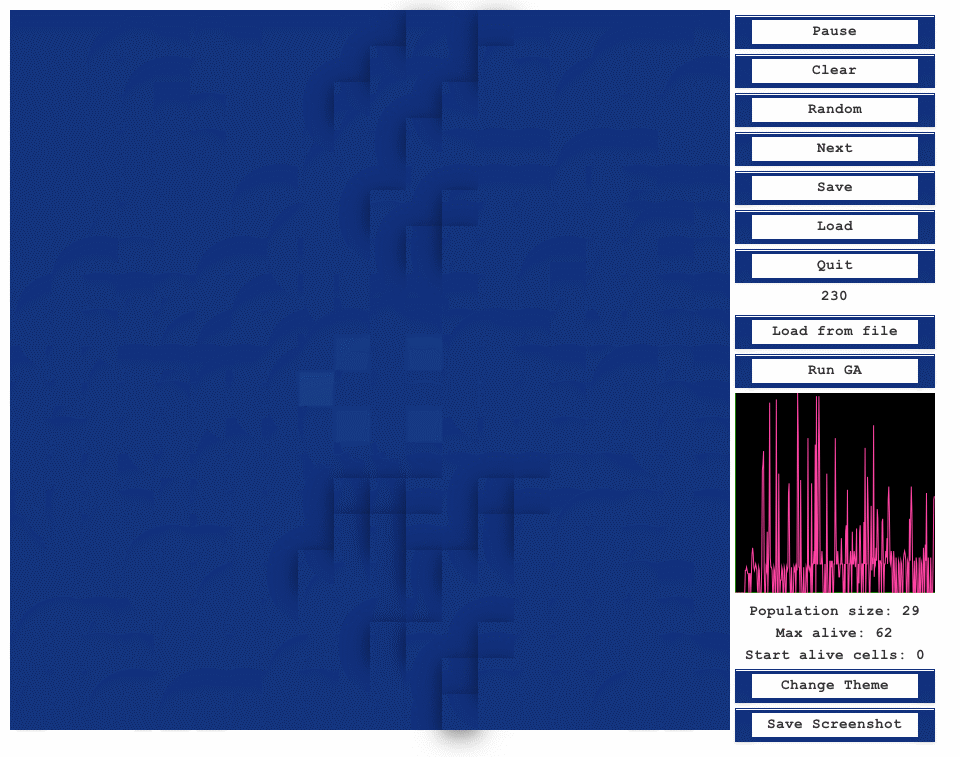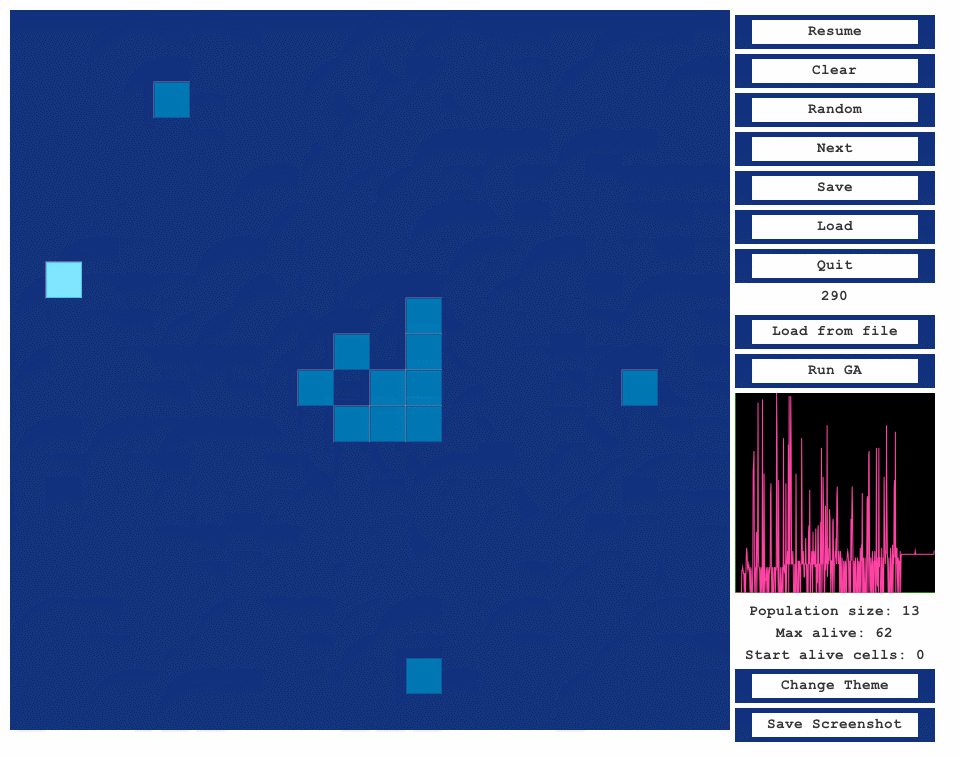
When the user is ready to run the genetic algorithm, they can press the Run GA button. The algorithm will continue
until the maximum number of generations is reached, at which point the final generation will be
displayed. See images/run_ga.gif
for a demonstration of the algorithm’s execution.
{kind=link}
After execution of the Run GA , a new
window displays the final generation, with the load from file button enabling navigation
through different individuals.

Window diaglog after final generation of the GA in the GUI
Note: The GUI prompts for a directory and remembers the last accessed location, simplifying subsequent runs within the same directory by eliminating the need for reselection. Command line executions automatically retrieve and open the last used directory.
Additionally, a save function is
integrated, allowing current configurations to be archived as .txt files within the saves directory for future access. This
feature is complemented by a Load button
for convenient retrieval of these saved configurations.
At any time users can personalize the interface’s appearance. To apply a custom theme, simply load
the desired css file via the Load CSS button. The GUI will automatically
update to reflect the new theme, enhancing the user experience. The deafult theme.css file is included for reference, as
well as 2 additional themes: theme2.css
and theme3.css. Note that too many visual
effect, such as box-shadow and border-radius can slow down the GUI. It is
recommended to use simple css files. For a
demonstration of the theme change, refer to imgaes/themes.gif.
{kind=link}
Using the Command Line
Note that the program can also be run without the GUI. In such cases, output is directed to the
console, and results are saved as .txt
files within the populations directory.
This approach was chosen to ensure program accessibility on any machine, regardless of the presence
of the gtk library, and to maintain output
configuration flexibility.
A notable drawback of this method is the storage inefficiency for sparse matrices in the populations directory. In different
scenarios, encoding these matrices would be a practical solution to conserve space. However, for
this specific application, the sparse matrices represent the desired output, making their direct
storage justifiable.
Examples
The evaluation of two distinct individuals, namely the T_shape and the Dragon shape, provides insightful
observations into the algorithm’s performance. The T_shape emerges as an intriguing pattern,
while the Dragon shape captivates with its
evolutionary complexity. These shapes frequently recur across various individuals, highlighting
their significance within the genetic algorithm’s exploration space.
To explore these examples firsthand, utilize the GUI’s Load button to access the saves directory or execute the following
commands:
../met saves/dragon.txt
../met saves/t_shape.txt
T_shape

T_shape Evolution in Inception theme
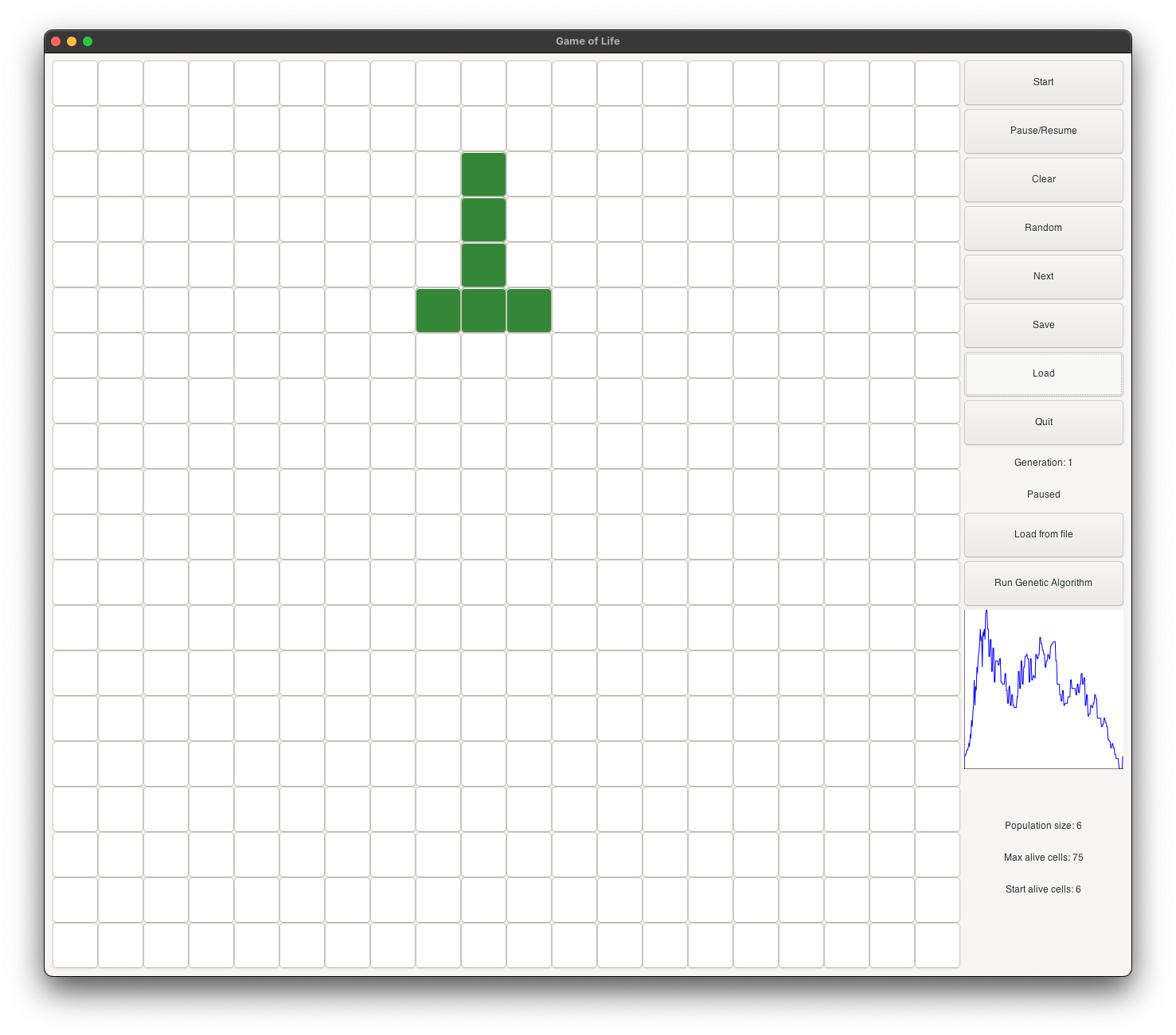
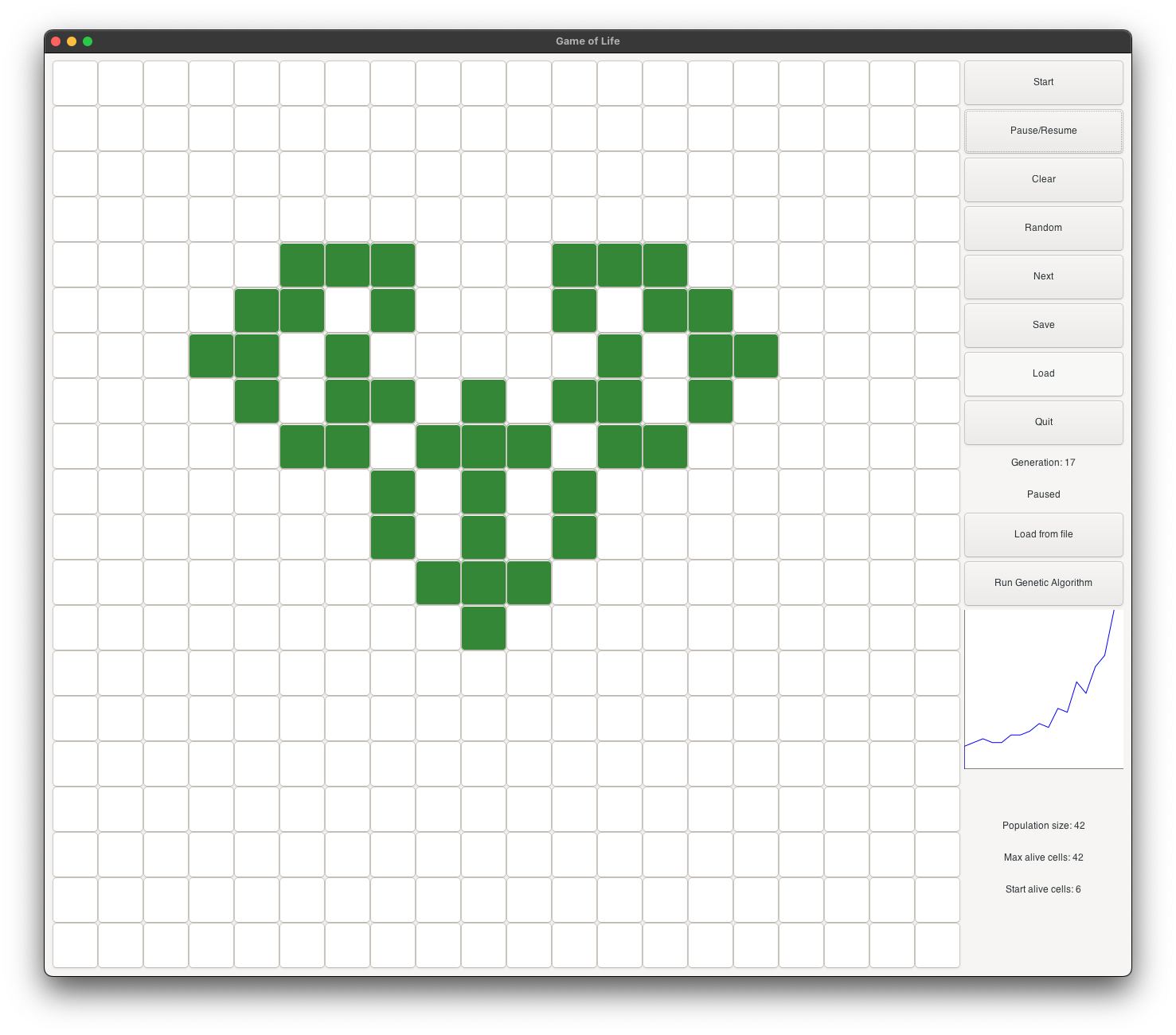
T_shape is called after the mighty T-rex,
and its T shape. The initial state starts
with 6 alive cells. It is a very small shape, and it is very likely to be selected as a parent for
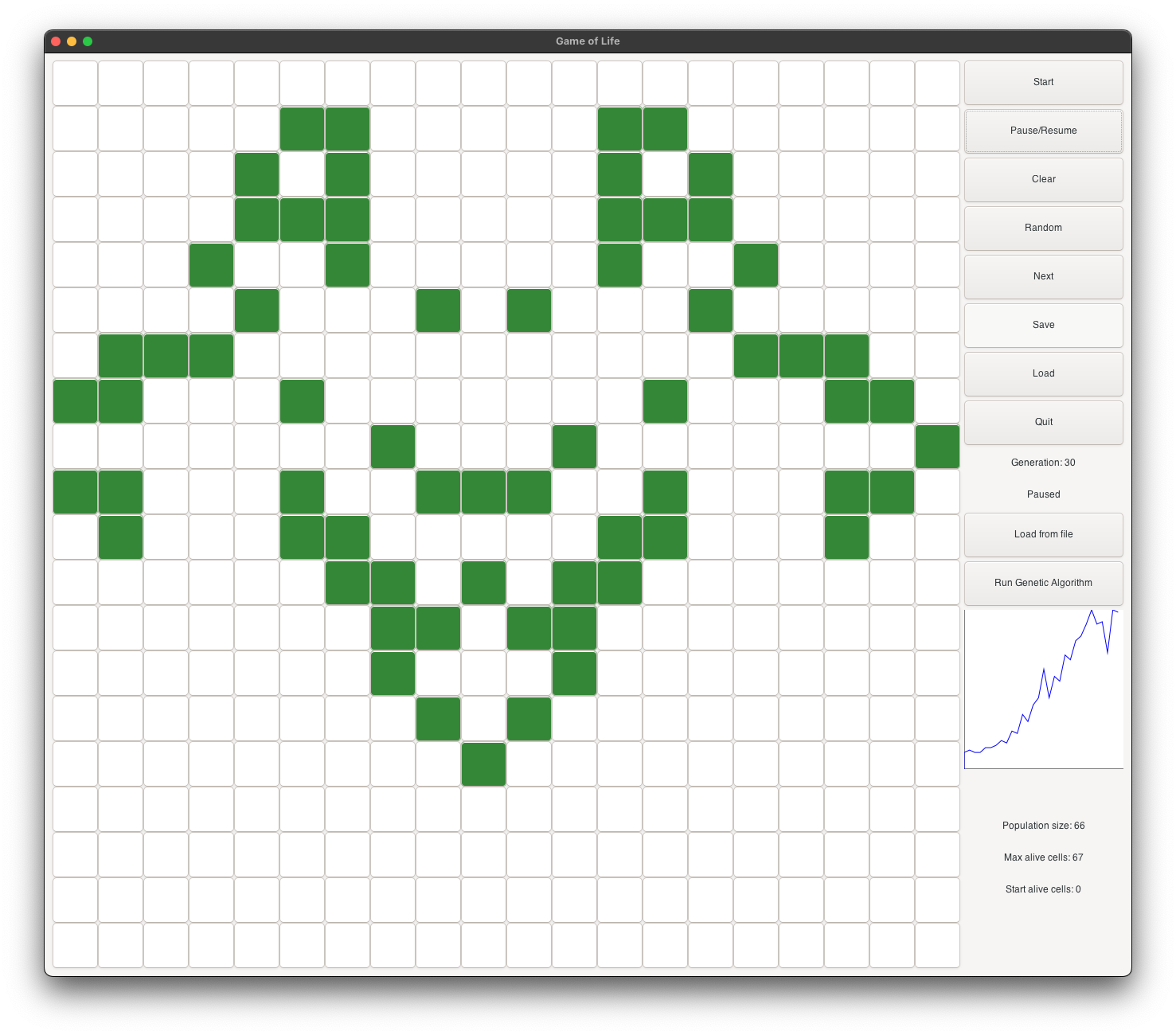
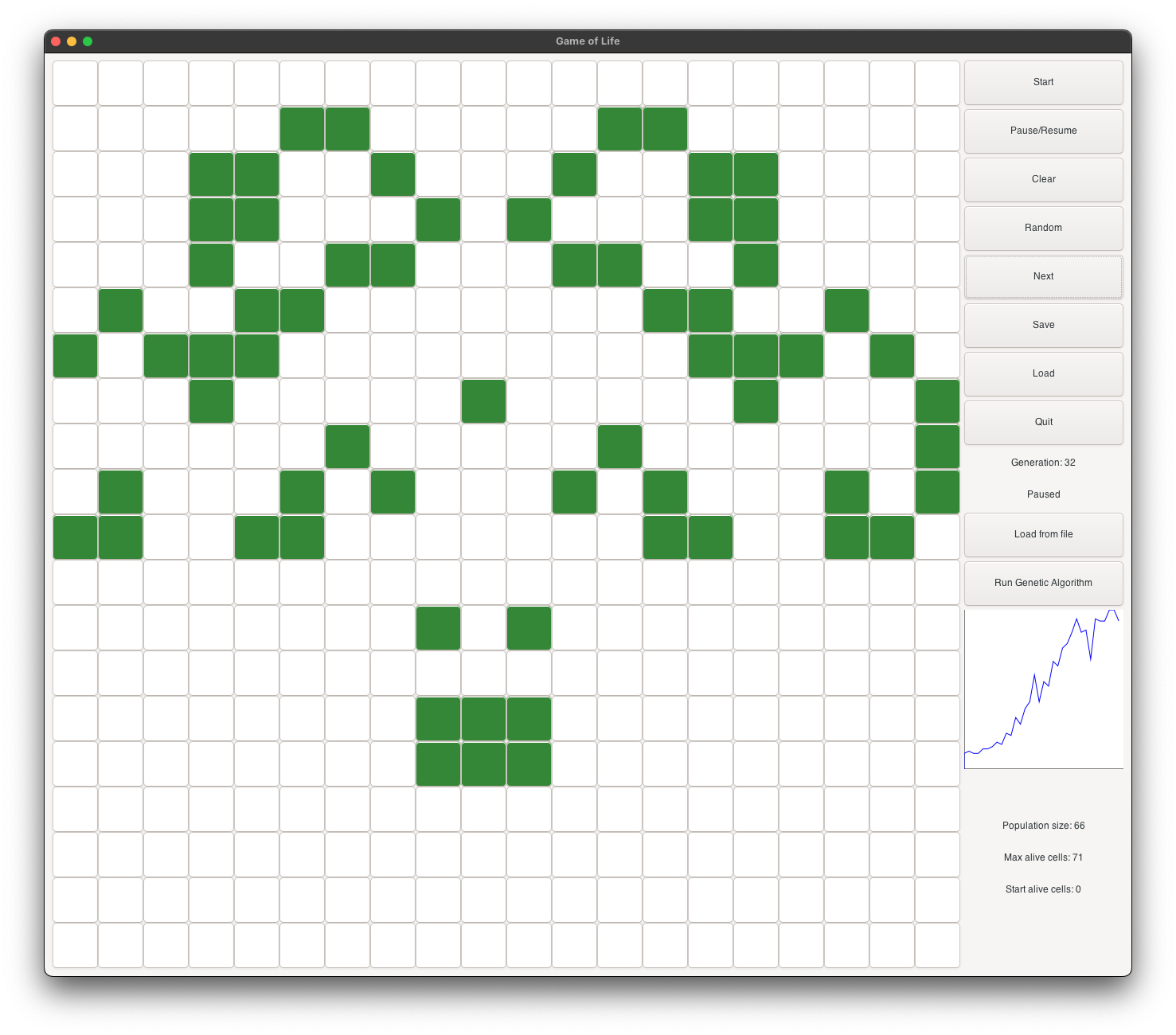
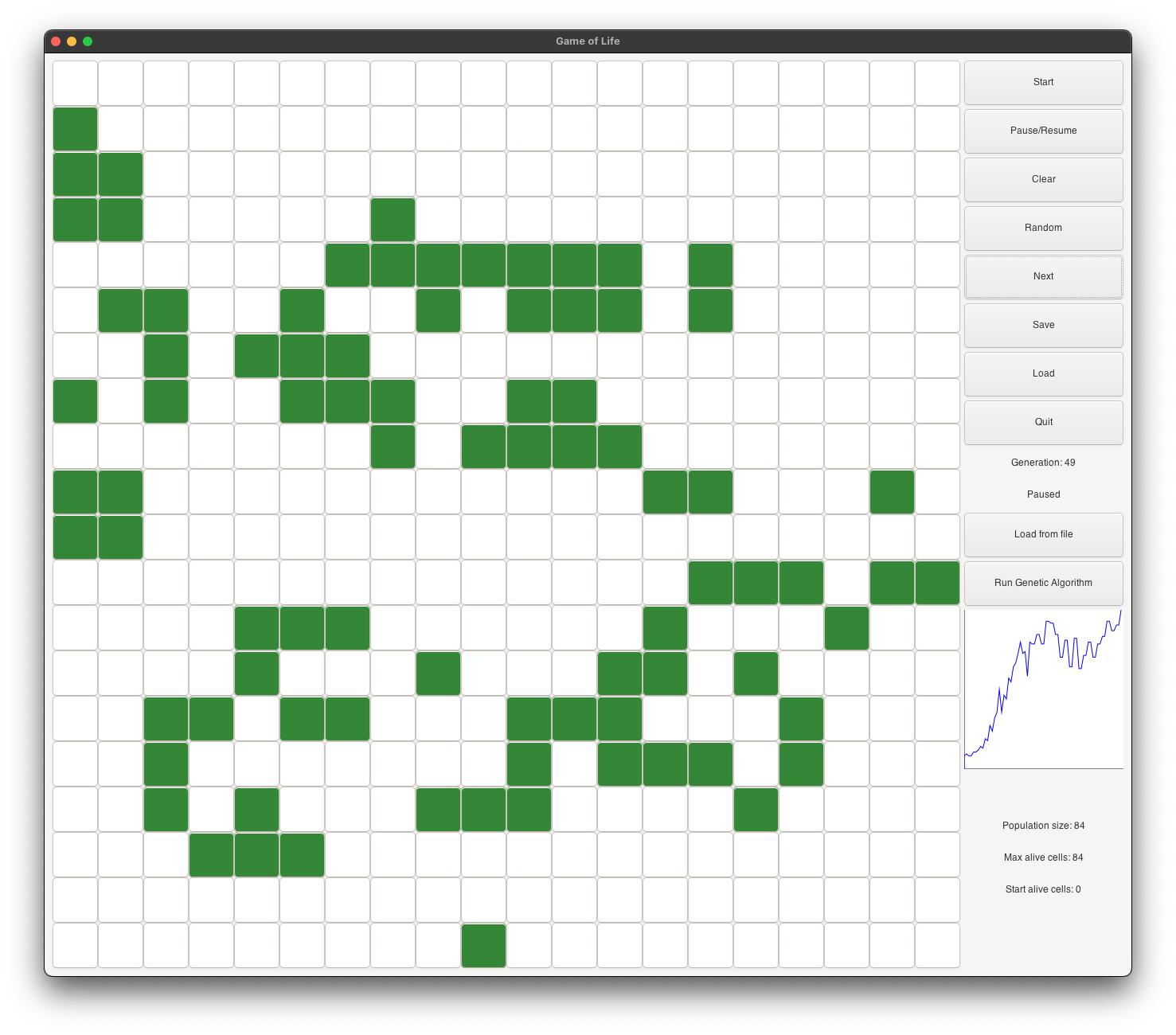
the next generation. It evolves into a heart (see figure 2), and continues as a musk (see figure 3).
It continues to evolve into a goat face (see figure 4), and then into a skull face (see figure 5).
It continues to grow and become stable at generation 225 (see figure 6). At its peak, it has about
100 alive cells.
Dragon

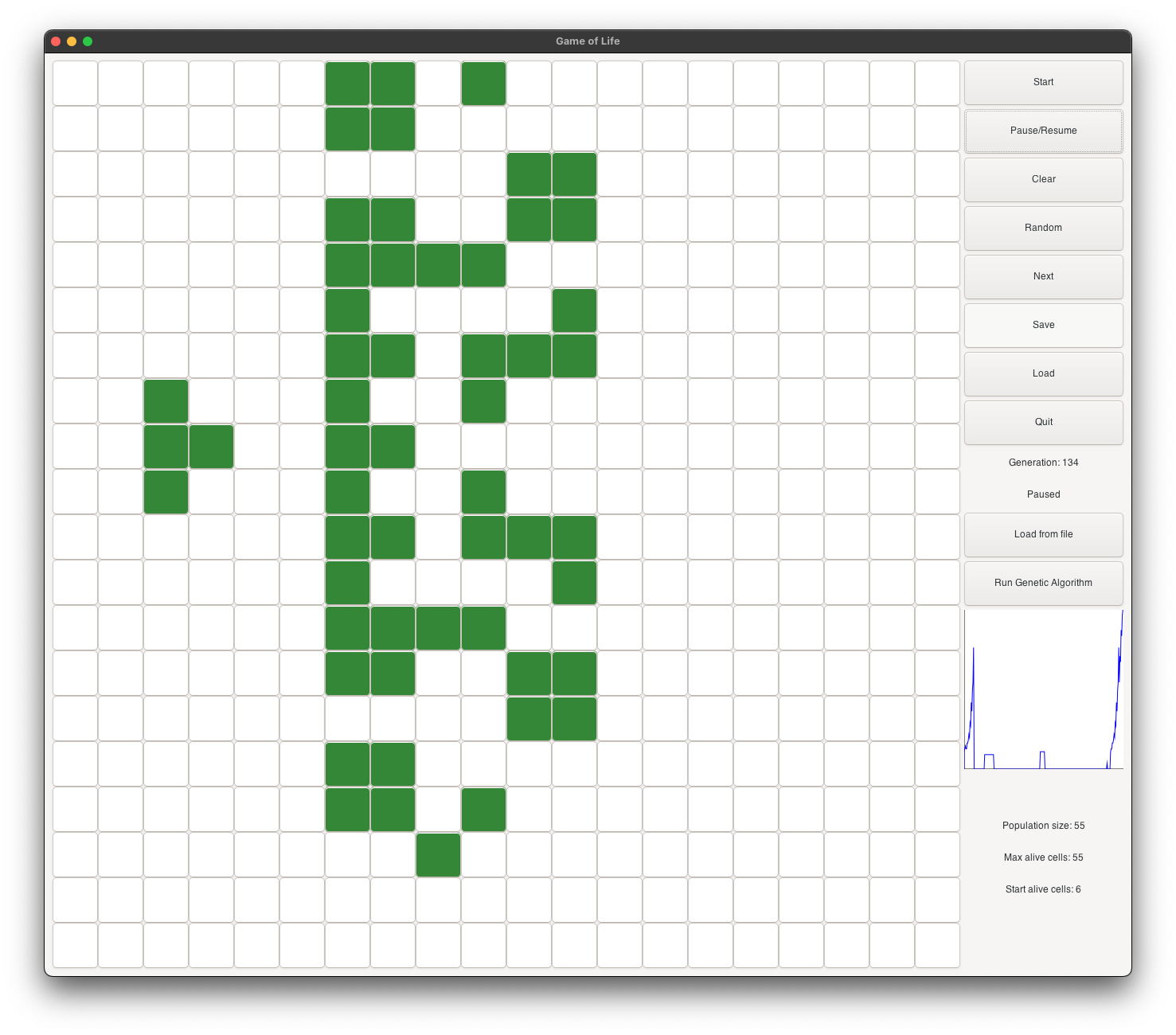
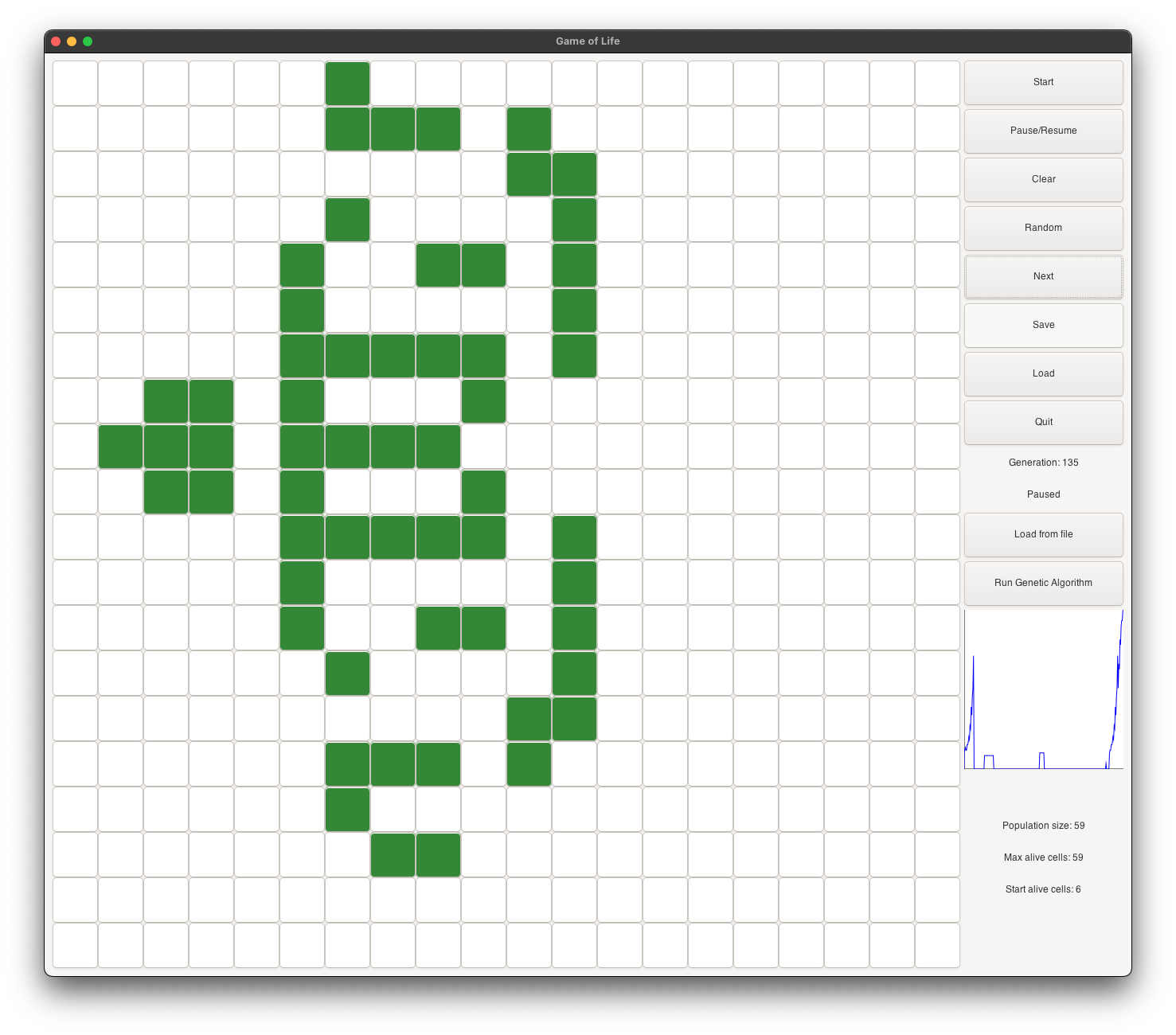
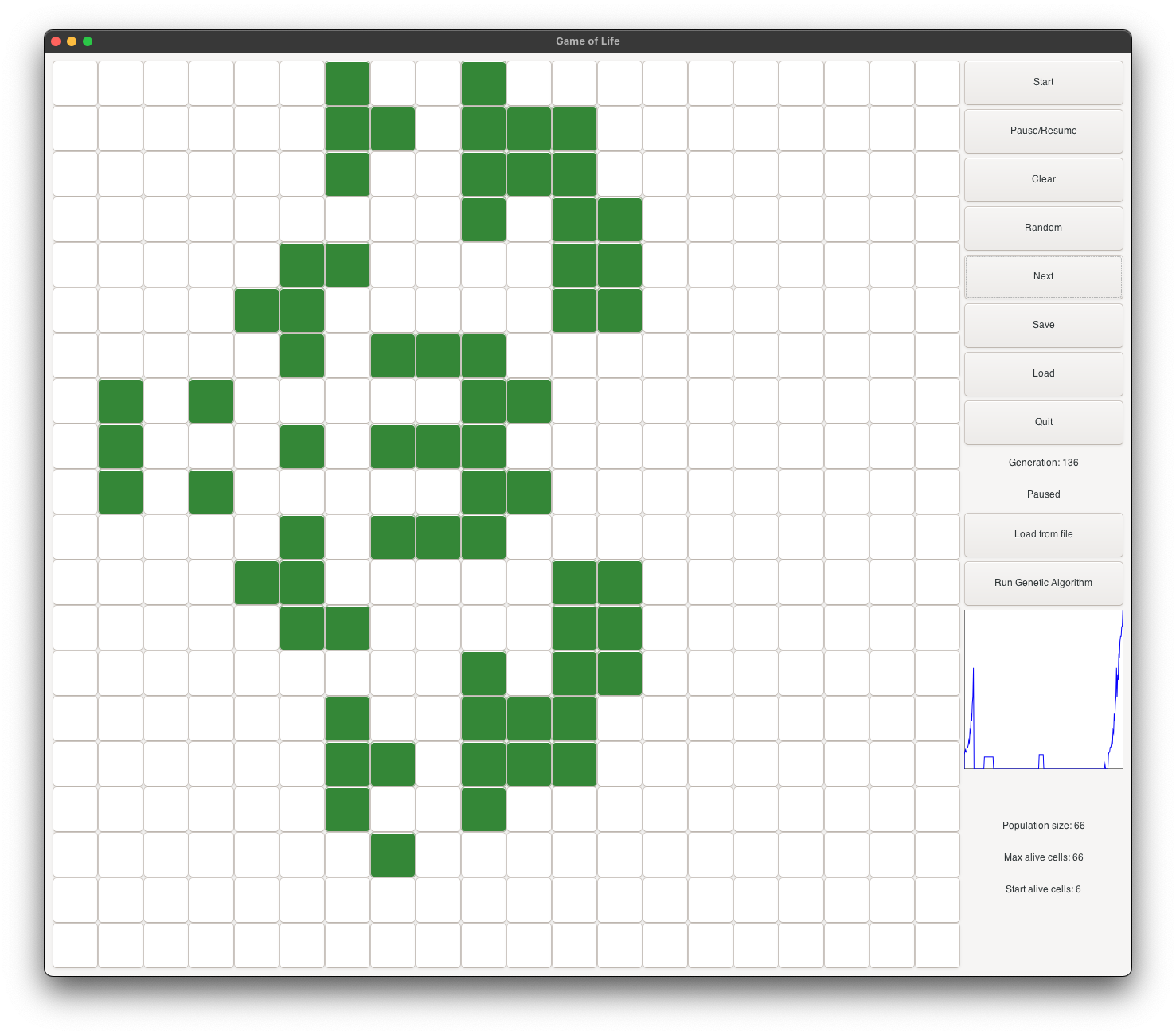
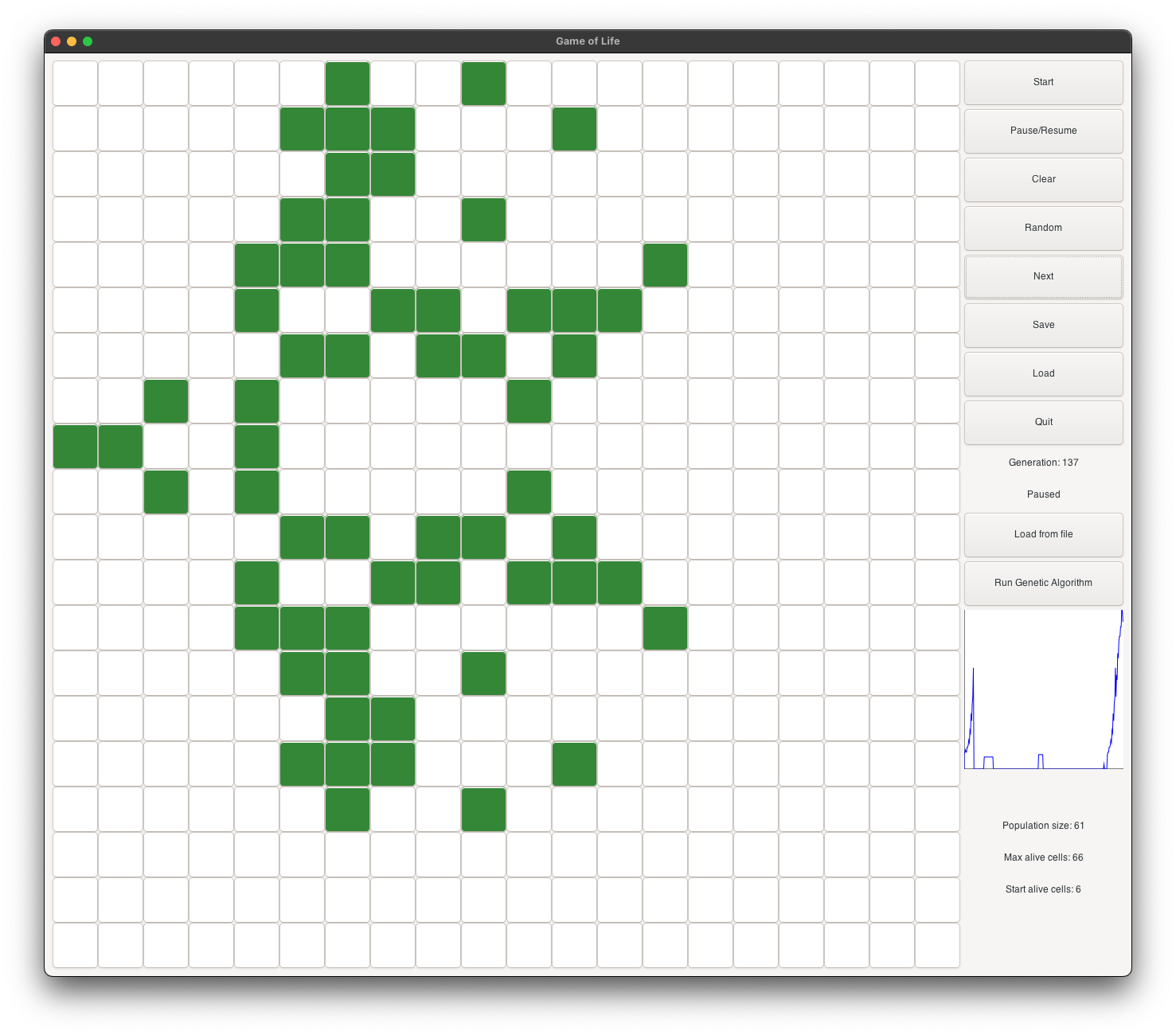
Dragon Evolution in red Inception theme
Dragon’s initial state starts with 6 alive cells. It is a very small shape, and it is very likely to be selected as a parent for the next generation. It evolves into a dragon with open wings (see figure 2), and continues as a dragon with closed wings (see figure 3). It continues to evolve into a dragon with big open wings (see figure 4), and then into a dragon with very big open wings (see figure 5). It continues to grow and become stable at generation 132 (see figure 6). At its peak, it has about 10 times more alive cells than the initial shape.
Hi

Hi Shape first 160 generations
The hi shape demonstrates a long evolution
period of more than 230 generations and more than ten times bigger than the initial shape.
You can see the population that led to those individuals under the populations directory and explore their variations.
More Examples


Evolution of fitted individuals in the GUI, light green theme (left) and purple theme (right)

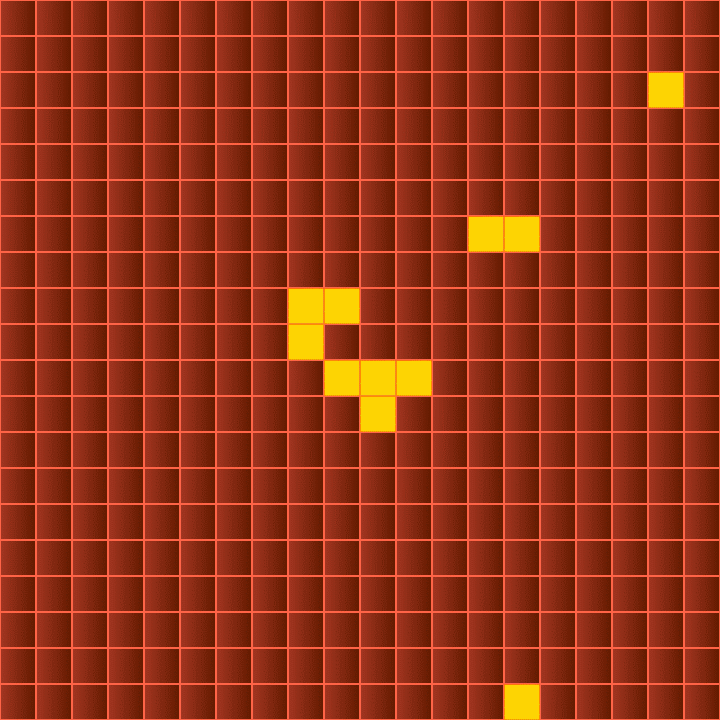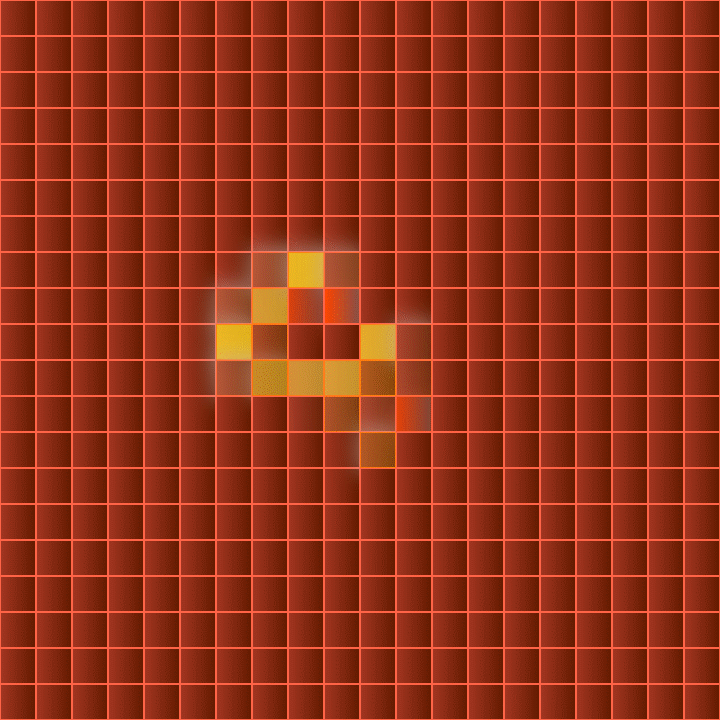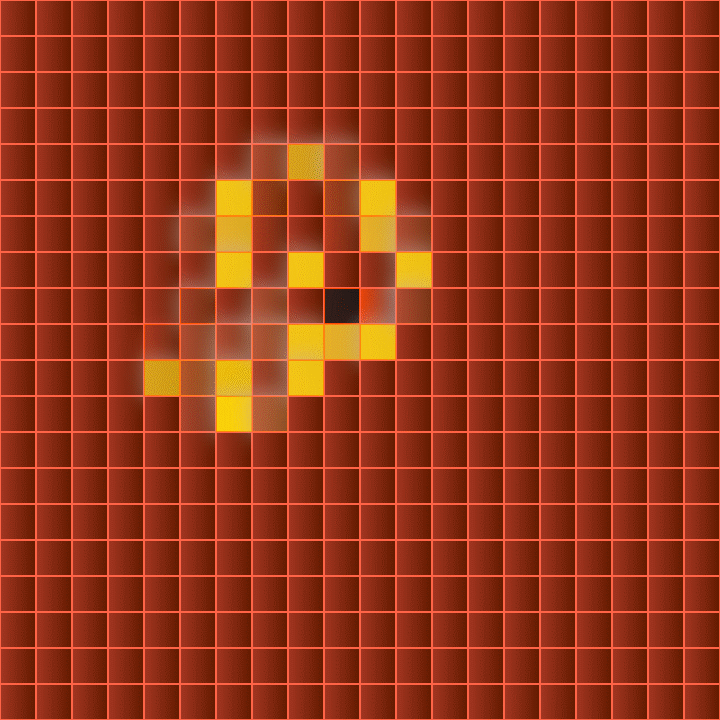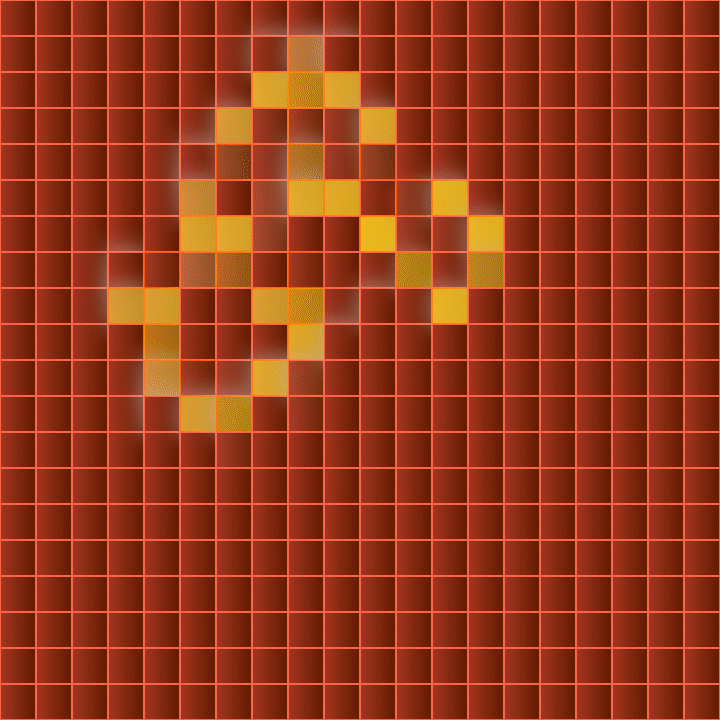
270 Generations of the Genetic Algorithm in the GUI, metal blue theme (left) and metal red theme (right)

Evolution of a fitted individual in the GUI, forest theme
267 Generations of the Genetic Algorithm in the GUI, metal red theme
Insights
The algorithm produced some interesting results. Here are more insights:
-
Short simulation tends to produce better individuals: This can be explained by the fact that mutations are most likely to turn cells alive than dead. This observation is based on the fact that the initial shapes are usually small, and the algorithm prefers to keep them small.
-
Low
mutationRatetends to produce better individuals: This can be explained by the fact that the best individuals are usually consist of the same basic shapes - like theT_shapeand theDragonshape. -
The algorithm prefers symmetric shapes: This can be explained by the fact that the evaluation function gives a bonus for bigger shapes. The bigger the shape is, the more likely it is to be symmetric.
-
The algorithm parameters are affected by the size of the board: This insight connects some parameters that at first sight might not seem related. For example, the number of simulations should align with the board size.
-
Cycles Tracking: To address undesired individuals surviving for a long time, a hash table that keeps track of visited boards during the simulation was added. To enhance performance, the boards are encoded into occurrences string, and the hash table is implemented as a
std::unordered_set<std::string>.
Technical Details
Game of Life Implementation
This section delves into the technical implementation of the Game of Life, highlighting specific optimizations. For details on the Genetic Algorithm implementation, please see the subsequent section.
Static Board Padding
To mitigate edge-related anomalies and simulate an infinite board, the implementation employs static padding around the board. This method enhances the simulation’s realism by ensuring edge cells have an equal opportunity for evolution as those in the center.
static int paddingRows[BOARD_SIZE + 2][BOARD_SIZE + 4];
// Ensure the board is only copied if there are differences
for (int row = 0; row < BOARD_SIZE; row++) {
if (memcmp(paddingRows[row + 2] + 2, board[row], BOARD_SIZE * sizeof(int)) != 0) {
for (int r = 0; r < BOARD_SIZE; r++) {
memcpy(paddingRows[r + 2] + 2, board[r], BOARD_SIZE * sizeof(int));
}
memset(paddingRows[0], 0, (BOARD_SIZE + 4) * sizeof(int));
memset(paddingRows[1], 0, (BOARD_SIZE + 4) * sizeof(int));
memset(paddingRows[BOARD_SIZE + 2], 0, (BOARD_SIZE + 4) * sizeof(int));
memset(paddingRows[BOARD_SIZE + 3], 0, (BOARD_SIZE + 4) * sizeof(int));
break;
}
}
This padding strategy not only simplifies the edge case handling but also optimizes memory usage by avoiding unnecessary copies of the board. The comparison step ensures the board is only updated when changes occur, reducing computational overhead.
Efficient Update Process
The update mechanism employs a two-bit strategy to encode both the current and next states of each cell within a single integer. This approach eliminates the need for a separate buffer to hold the next state, thereby halving memory usage and improving performance.
// Apply game rules and set the next state in the second bit
for (int row = 2; row < BOARD_SIZE + 2; row++) {
for (int col = 2; col < BOARD_SIZE + 2; col++) {
int liveNeighbors = calculateLiveNeighbors(paddingRows, row, col);
if (paddingRows[row][col] & 1) { // Current state is alive
if (liveNeighbors == 2 || liveNeighbors == 3)
paddingRows[row][col] |= 2; // Survives
} else { // Current state is dead
if (liveNeighbors == 3)
paddingRows[row][col] |= 2; // Becomes alive
}
}
}
// Finalize the state transition by shifting bits
for (int row = 2; row < BOARD_SIZE + 2; row++) {
for (int col = 2; col < BOARD_SIZE + 2; col++) {
paddingRows[row][col] >>= 1; // Complete the transition
board[row - 2][col - 2] = paddingRows[row][col] & 1; // Update the main board
}
}
This bit manipulation technique allows for an in-place update of the board state, significantly optimizing the simulation’s performance.
Inspiration for this optimization came from solving a related problem on LeetCode, where I first encountered Conway’s Game of Life. You can explore my solution, originally written in C, in my December 2023 LeetCode post here. If you find the approach insightful, I would appreciate your upvote.
Note: The board utilizes a fixed-size array (int [size][size]), chosen for its simplicity
and efficiency due to compile-time size knowledge and contiguous memory allocation. Adjusting the
BOARD_SIZE macro in config.hpp allows for easy size modifications.
Chromosome Representation
The Chromosome class encapsulates a
configuration of Conway’s Game of Life.
Initial State
The initial population is generated by the Population class through the Chromosome default constructor, which
creates a random configuration at the board’s center. This task proved more complex than
anticipated. The challenge was to ensure the initial configuration was random, yet small and
diverse. My solution involved:
-
Selecting an
aliveProbabilityparameter (detailed in config.hpp). This parameter dictates the likelihood of each cell being alive. -
Defining lambda functions to outline basic shapes:
square,circle, andtriangle. These functions accept cell coordinates and returntrueif the cell resides on the shape’s border, andfalseotherwise. -
Adjusting weights for each shape to mitigate biases, as certain shapes tended to have a higher probability of containing alive cells, which I aimed to avoid.
-
Choosing a random shape.
-
Iterating over the board, setting each cell within the chosen shape’s border to be alive based on the
aliveProbability.
Note: By confining the initial configuration to the middle of the board, I’ve
effectively reduced the search space. According to the assignment’s requirements, we are permitted
to assume a finite space. Additionally, I implemented dynamic sizes and tested the algorithm on
various board sizes. The size factor can be adjusted by modifying the BOARD_SIZE macro in config.hpp. However, it is recommended to maintain a
value of 20 to guarantee optimal results.
Crossover (The Binary Genetic Operator)
Crossover implementation in the Chromosome
class constructor:
Chromosome(std::shared_ptr<Chromosome> parent1,
std::shared_ptr<Chromosome> parent2);
After thorough testing of various crossover methods, I opted to forgo the point crossover method described on pages
94-95 of the book (Biological Computation). Instead, I chose the uniform crossover approach. This method is
encapsulated within the Chromosome class
constructor. The constructor accepts two parent chromosomes and generates a new chromosome by
randomly selecting each cell’s state from one of the two parents.
for (int row = 0; row < BOARD_SIZE; row++) {
for (int col = 0; col < BOARD_SIZE; col++) {
if (rand() % 2 == 0) {
board[row][col] = parent1->board[row][col];
} else {
board[row][col] = parent2->board[row][col];
}
}
}
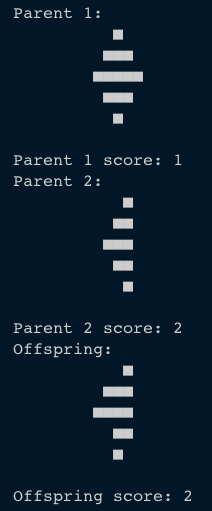
Another example to crossover (`aliveProbability` is 100% for this example)
Note that the crossoverPointX ctor is also
implemented, and you can use it by calling the following constructor:
Chromosome(int crossoverPoint, std::shared_ptr<Chromosome> parent1,
std::shared_ptr<Chromosome> parent2);
Mutation
The mutation process is uniquely orchestrated outside the Chromosome class, specifically within the
Population class through a mutation method. This method requires a
mutationRate parameter and applies
mutations across the population with a probability determined by this rate. The mutation operation
involves randomly selecting a cell (or Gene) within a chromosome and toggling its state.
Strategically situating the mutation functionality outside of the Chromosome class. It allows for a
comprehensive application of mutations across all chromosomes within the population, rather than
restricting mutation to individual chromosomes. This approach ensures that the mutation process can
consider the entire population’s genetic diversity when applying changes.
The mutation methodology employed here aligns with the uniform mutation strategy as discussed on
page 95 of the book (Biological Computation). By applying mutations uniformly across the population,
this method enhances the likelihood of generating viable and diverse genetic configurations.
An important aspect of our mutation strategy is its focus on the central region of the chromosome for mutation application. This focused approach ensures that mutations have a meaningful impact on the genetic configuration, thereby supporting the generation of viable and diverse outcomes. The following code snippet illustrates how mutations are specifically applied to the central region of the chromosome:
void Population::mutation(double mutationRate) {
// Random mutation based on mutation rate
for (auto &individual : chromosomes) {
for (int i = 0; i < BOARD_SIZE; i++) {
for (int j = 0; j < BOARD_SIZE; ++j) {
if ((rand() / (double)RAND_MAX) < mutationRate) {
individual->board[i][j] =
1 - individual->board[i][j]; // Flips the bit
}
}
}
}
}
Evaluation Function
To pinpoint the desired configurations, a specialized evaluation function was crafted, encapsulated
within the calculateScore method. This
function draws upon three critical insights:
- The longer it takes for the configuration to reach a stable state, the more favorable it is.
- The larger the configuration grows during its evolution, the better.
- The smaller the initial configuration, the more advantageous.
These principles are operationalized in the evaluation process, where each chromosome undergoes a
simulation spanning 500 generations. For every generation a chromosome remains stable, it earns +1
to its score. Post-simulation, the score is determined by the formula: std::max(1, maxAlive - static_cast<int>(startAlive*2.2) + stablePeriod);.
Here, maxAlive is granted a 100% bonus to
promote the development of larger configurations—a decision reached after extensive testing.
Conversely, startAlive incurs a 120%
penalty to favor smaller starting configurations, while stablePeriod enjoys a 100% bonus,
incentivizing longer-lasting simulations. The use of std::max(1, ...) ensures that scores do not
dip into the negative.
Stable states are detected using prevAlive
and curAlive variables, alongside a pastStates hash table. The pastStates table checks if a current state
has previously occurred by transforming the board into a run-length encoded string, converting
sequences like 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 1 1 1 1 into
0#4 1#3 0#7 1#4. This encoding
significantly reduces the hash table’s size and accelerates comparisons. While prevAlive and curAlive could also indicate stability,
employing the hash table method is markedly more efficient.
Fitness vs Score
In the context of genetic algorithms within this program, each chromosome is characterized by two
distinct attributes: score and fitness. The score reflects the chromosome’s performance
in the simulation, serving as a measure of its effectiveness in reaching desirable states. On the
other hand, fitness quantifies the
likelihood of a chromosome being chosen for reproduction in the subsequent generation.
The calculation of fitness is derived from
the score of an individual chromosome in
relation to the aggregate score of the entire population. Specifically, fitness represents a proportion of the total
score, ensuring that chromosomes with superior scores are accorded higher fitness values.
Consequently, these chromosomes stand a better chance of being selected for the next generation,
aligning with the principle that the fittest individuals have the greatest likelihood of survival
and reproduction.
Population Implementation
The Population class encapsulates a
collective of Chromosome instances,
managing their lifecycle and evolutionary processes. Implemented in population.cpp, this class oversees a vector of
chromosomes, std::vector<std::shared_ptr<Chromosome>> chromosomes,
handling tasks such as selection and crossover to foster the development of successive generations.
Selection within the population is governed by selectionPressure and selectionMethod parameters. selectionPressure dictates the count of
chromosomes to be selected, while selectionMethod determines the technique of
selection. These selection strategies are detailed in the GeneticAlgorithm class, which will be
explored further.
Crossover (Reproduction Part)
To regenerate the population for the next generation, the Population class leverages the Chromosome API, utilizing selectionPressure and the chosen selection
method to guide the process. This design ensures versatility, enabling the class to support a wide
array of problems beyond the specific challenge addressed by this program. The aim is to foster a
generic, adaptable framework for genetic algorithm applications.
void Population::crossover() {
// create a new population
std::vector<std::shared_ptr<Chromosome>> newPopulation;
// Generate new individuals until the new population is full
while (static_cast<int>(newPopulation.size()) < populationSize) {
// Select two parents
int parent1Id = rand() % chromosomes.size();
int parent2Id = rand() % chromosomes.size();
// Perform crossover
std::shared_ptr<Chromosome> parent1 = chromosomes[parent1Id];
std::shared_ptr<Chromosome> parent2 = chromosomes[parent2Id];
auto offspring = getOffsprings(parent1, parent2);
// Add the new individuals to the new population
newPopulation.push_back(offspring[0]);
newPopulation.push_back(offspring[1]);
// If the new population is not full, add the fittest parent to the new
// population
if (newPopulation.size() < chromosomes.size()) {
newPopulation.push_back(chromosomes[parent1Id]);
}
}
// Replace the old population with the new population
chromosomes = newPopulation;
}
GetOffsprings simple calls the Chromosome constructor with the two parents
that were selected from the survivors
selected by the selection method. The
process is repeated until the new population is full.
After each generation is created - including the initial one, the calculateScore method is called on each
chromosome to calculate its score.
The method updates the fitness of each chromosome based on the score and the total score of the
population. The fitness is calculated by the following formula: fitness = score / totalScore.
// update the fitness score for each chromosome
for (auto chromosome : chromosomes) {
chromosome->calculateFitness(static_cast<double>(totalFitnessScore));
}
Note that due to the way the rouletteWheelSelection method is implemented, the totalFitnessScore is actually the totalScore of the population.
Because it takes for each chromosome its score, in relation to the total score, the fitness is actually a percentage of the total score. This way, the chromosomes with the highest scores get the highest fitness, and the chromosomes with the lowest scores get the lowest fitness.
Genetic Algorithm Implementation
The GeneticAlgorithm is imlemented based on
the psudo-code describe in p. 131 of the book (Biological Computation). The class is implemented in
ga.cpp. The class is responsible for running the genetic
algorithm on the population of chromosomes.
The main process is implemented in the run
method.
void GeneticAlgorithm::run() {
while (population->generation < maxGenerations) {
population->calculateTotalScore();
report();
population->selection(selectionPressure,
&GeneticAlgorithm::rouletteWheelSelection);
population->crossover();
population->mutation(mutationRate);
population->generation++;
}
population->calculateTotalScore();
save();
printSummary();
}
Roulette Wheel Selection
After testing different kinds of selection methods, I’ve decided to use the Roulette Wheel Selection method. This method
is implemented in the GeneticAlgorithm
class. The method is implemented in the selection method. The method gets the selectionPresure parameter and returns a
vector of selected chromosomes.
void GeneticAlgorithm::rouletteWheelSelection(
std::vector<std::shared_ptr<Chromosome>> &chromosomes, int survivorsSize) {
std::vector<int> cumulativeScores(chromosomes.size());
int totalScore = 0;
for (int i = 0; i < static_cast<int>(chromosomes.size()); i++) {
totalScore += chromosomes[i]->score;
cumulativeScores[i] = totalScore;
}
std::vector<std::shared_ptr<Chromosome>> survivors;
while (survivors.size() < survivorsSize) {
int random = rand() % totalScore;
auto it = std::lower_bound(cumulativeScores.begin(),
cumulativeScores.end(), random);
int index = std::distance(cumulativeScores.begin(), it);
survivors.push_back(chromosomes[index]);
}
chromosomes = survivors;
}
Note that the selectionPressure parameter
is used to determine the number of chromosomes to select (survivorsSize) by applying the following
formula: survivorsSize = (int)(chromosomes.size() * selectionPressure).
Report
The report method is designed to provide a
visually engaging overview of the algorithm’s progress. Initially, I utilized csv files for tracking, but later
transitioned to real-time console output for a more dynamic observation experience. Given the
algorithm’s rapid execution, the progress visualization resembles a fast-forward movie.
The bestChromosome is displayed in an
accessible format, utilizing square (■)
and space symbols to represent different states or values.
I encourage you to experience the evolution process in real-time. For a demonstration, please refer to attachment A.
Save
The save method facilitates the
preservation of algorithm outcomes. Each member of the final population is saved into a .txt file, prioritized by performance with
the file names reflecting the score of the individual. Additionally, a comprehensive report.txt file compiles the algorithm’s
parameters, the concluding population, and a summary of the process. The report delineates each
individual with detailed descriptions and includes command line instructions for replicating the
experiment with specific individuals. An example can be found in attachment B.
Contributions and Feedback
Feel free to fork this project, submit pull requests, or send me suggestions to improve the algorithm or the implementation. Your feedback is highly appreciated!
Acknowledgements
This project was inspired by my continuous exploration of computational biology and my desire to blend software engineering with biological systems’ complexity. Special thanks to my course instructors and peers for their invaluable insights and support.
License
This project is licensed under the MIT License - see the LICENSE file for details.